tl;dr: File handling at troupeIT is much improved. Uploads and large file support (to 1 GB), multiple file support solidly supported, and considerably faster downloads, supported by a world-wide content-delivery network. Read on for the engineering.
Recently, we completed a major change of TroupeIT's file upload/download system. Here's a quick flowchart if you want to follow along.
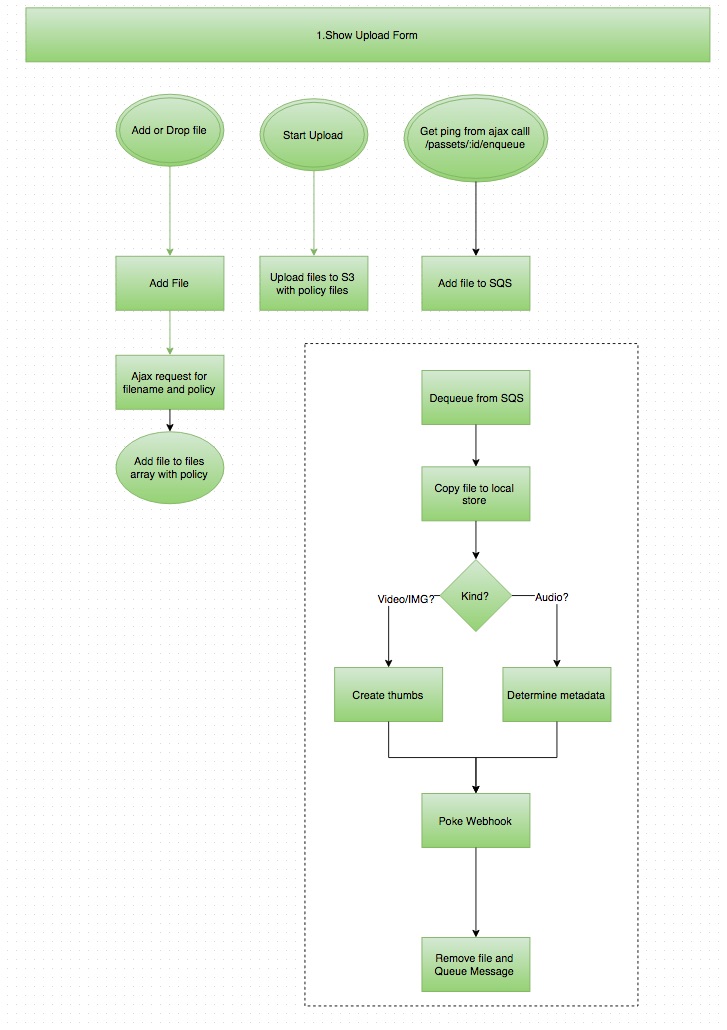 Until recently, uploads were handled by a small number of servers and written directly to disk on application servers. Metadata and thumbnail/preview processing was performed synchronously in the request pipeline, while the user waited for the file to be analyzed and thumbnails created (ew.)
Until recently, uploads were handled by a small number of servers and written directly to disk on application servers. Metadata and thumbnail/preview processing was performed synchronously in the request pipeline, while the user waited for the file to be analyzed and thumbnails created (ew.)
Users also had occasional complaints when uploading very large files, because our application servers would timeout on copy or failure.
Post-processing of files can take a considerable amount of time and we'd rather not have our users wait for this processing to take place. Now, when uploads complete we can perform the vast majority of these tasks asynchronously.
All of our uploads are handled by a custom React JSX component that wraps plupload. When a user adds a file to their upload queue by drag/drop, or selection, we get a BeforeUpload event, and that gives us a chance to request an policy ticket (and new Passet record) from our servers. This policy is used to authenticate the request to S3 and to permit writing to our troupeit-uploads bucket for a very small amount of time (about a minute or so.)
We perform an auth request for every file added. Previously, we'd disregard anything beyond the file added to your upload queue, but now this queuing system allows us to support multiple file uploads in your queue.
Once each file upload finishes, the FileUploaded message fires in your browser. Unfortunately, we can't get a callback from Amazon, but we can use some JS to force the browser to notify us when the file has been uploaded, via Ajax. This endpoint also enqueues a message inside of Amazon SQS in our upload_processing queue so your previews can be built.
We then reload the filelist in your file manager to show the new files in a pending state. At this point we have little more than the title, filename, and file size. A javascript timer completes the UX response, continually reloading your file list until all files clear the 'pending' state.
So far, all of this has taken (not including your upload) well under one second.
At the same time, The Shoryuken worker system wakes one of it's worker threads after dequeuing your request from Amazon SQS. The worker then downloads your file from S3 for analysis.
It fires off [exiftool(http://www.sno.phy.queensu.ca/~phil/exiftool/) through the Miniexiftool gem and other utilities like ffmpeg, to determine metadata about your file, such as width, height, song title, mime type, artist, bitrate, and duration.
When this completes (in about 500mS) we ping a webhook back on our private API to indicate that file processing is finished and that the file is ready for use, clearing the pending state on the file.
This whole process takes around 1-3 seconds to complete, is highly scalable across many servers, and very available thanks to Amazon S3 and SQS.
We also had a bit of a migration headache after these changes, moving nearly four years of uploads into S3, but that was handled readily with a rake task that reused most of the old upload code, renaming files into a standardized format.
What about downloads?
Downloads are done through Amazon Cloudfront, connected to our Amazon S3 bucket.
As far as show and event ZIPs go, we're beginning to explore getting TroupeIT off of Rails and on to services on Go. For one of our first projects in Golang, we've written a micro service for downloading shows as ZIP files. Your browser provides us with a show_id for donwload and authentication. We hand you a zip back after we validate your request against our database, using a private API.
The key difference between this service and our previous approach is that we are able to build the ZIP as a streaming buffer, directly to the user's browser. Our old, time consuming method of "copy all of the files to a directory, ZIP up the files, and then send the stream" is no longer used. Now we can stream an authenticated, HTTPS stream directly to the user, with our first byte leaving the server just as soon as the user clicks.
This also eliminates the setup and page load lag we once had on the Download page.
Progress! Onward!
P.S. Did I mention we're now using Ghost for our blog? It's beautifully designed and much less hassle than Wordpress.